背景
Boltzmann 形式的分布
在广泛的条件下,统计力学所关心的微观状态 x 的平衡概率符合如下分布
x∼Cexp(−u(x))(1)
最为著名的例子就是 Boltzmann 分布。(1) 中的标量能量项 u(x) 包含系统的势能、温度和可选的其他热力学量。
基于轨迹的方法: MCMC/MD
由于现阶段除去少量的模型体系外,并没有直接从 Boltzmann 分布中得到 one-shot 的样本 x 的方法,因此,往往使用依赖于轨迹的方法例如马尔科夫链蒙特卡洛 (MCMC) 或分子动力学 (MD) 等方法通过在每一步中逐渐微调 x 来对系统进行采样。由于复杂系统中亚稳态的广泛存在导致在这些状态中相互转换成为了罕见的事件 (rare events) ,这类方法往往需要非常长的时间才能得到平衡分布。这个特点使得 MCMC/MD 非常昂贵。
基于 CV 的增强抽样
为了克服 MCMC/MD 中对罕见事件的采样问题,一种常见的方法是对人为定义的的集合变量 (collective variables) 或称反应坐标 (reaction coordinates) 进行偏置 (biasing) 来加速这一过程。然而,这往往需要比较多的先验信息。对于复杂的高维系统,受限于难以获得有效的 CV 以及在其他的未偏置的方向上的能垒难以避免,这一方法很难应用。
Boltzmann Generator
Frank Noé 等人基于深度学习构建了 Boltzmann Generator (以下简称为 BG) 用以解决复杂势能面上的采样问题,其主要思路是将复杂系统的采样转化为一个简单分布的生成和从生成得到的分布向目标分布的可逆变换两个部分。通过训练一个可逆的神经网络,BG 将 x 映射到隐空间上的坐标表示 z,其中不同状态的低能量配置彼此接近并且可以容易地采样 (e.g. 高斯分布)。由于 BG 是可逆的,因此,对 z 的采样经过一个逆向的变换,就可以得到原有微观状态 x 的分布,这将与原有的 Boltzmann 分布非常接近,此时,经过一个简单的重加权就可以得到原有的 Boltzmann 分布。
概览
在 BG 的框架下,对系统的采样主要需要进行如下步骤
- 训练一个神经网络 Fzx 使得从简单的先验分布生成 z 后,Fzx(z) 将产生一个构想 x 使得 x∼pX(x)。其中的分布 pX(x) 是一个接近于目标 Boltzmann 分布的分布。
- 为了得到无偏的样本并计算在原有分布上的期望,对得到的 pX(x) 进行重加权,例如对于每一个样本应用如下的权重
w(x)=e−u(x)/pX(x)
然后计算相关的统计量。
这一过程示于下图中
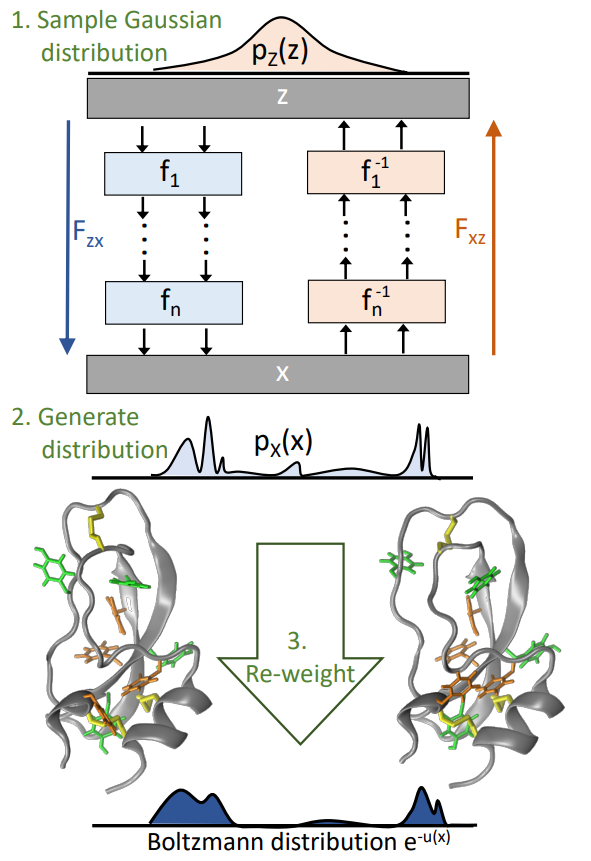 Boltzmann Generator
Boltzmann Generator 分布的变换
无论在训练过程还是重加权过程中,对于生成构想 x 的概率 pX(x) 的计算都是关键。当神经网络 Fzx 可逆时,这样的生成可以比较简单地进行。物理上,可逆变换类似于将概率密度从构象空间变换到潜在空间或反向的流体流动,因而,可以借助生成模型中的流模型进行处理。通常,保持体积的分布变换可以类比为不可压缩的流体,而 BG 中采用的是允许体积变化的分布变换,对应于可压缩流体的行为,因为这类模型允许在构象空间的不同部分不同地缩放概率分布。这一切的基础是可逆的神经网络结构:
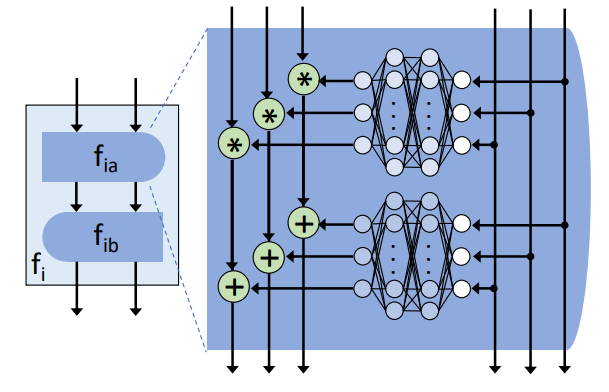 Invertible Neural Block
Invertible Neural Block 模型的训练
主要分为两种模式: 基于能量的训练和基于例子的训练
Energy-based
采样 z 变换得到 x=Fzx(z),进而得到 pX(x)。最小化 pX(x) 和原有的 Boltzmann 分布之间的差距,其中的度量可以选择 Kullback-Leibler Divergence 等。
JKL=Ez[u(Fzx(z))−logRzx(z)]
其中 Rzx 是 BG 的 Jacobian 矩阵的秩。将 KL 散度作为损失函数,可以进行 BG 的训练。同时,KL 散度等价于从生成 z 使用的先验分布到生成的分布之间的自由能变: 表达式中的第一项代表系统的平均势能,而第二项等价于在选定温度下的熵贡献 (相差常数)。 因而,这样一个损失函数决定了模型倾向于采样低能量的结构,且可以避免模式崩塌 (mode-collapse)。
Example-based
仅仅使用基于能量的训练将使得模型有对于最稳定的亚稳态的偏好,为了处理这一问题,需要追加基于数据实例的训练。通过选取一些合法的构象 x (通过短 MD 等方式或使用实验数据等),并将其映射得到 z=Fxz(x)。此时可以进行最大似然的训练:
JML=Ex[21∥Fxz(x)∥2−logRxz(x)]
这样基于例子的训练往往在训练早期引入,从而引导 Fzx 关注状态空间中我们感兴趣的部分。
重要细节
可逆的可训练层: RealNVP
将变量分为两个通道 x=(x1,x2),z=(z1,z2),在每一个通道上只进行可逆的加法和乘法操作。使用任意的,无需可逆的神经网络 S 和 T 分别使用第一个输入通道 x1 的非线性变换对第二个输入通道 x2 进行缩放和平移:
fxz(x1,x2):logRxz=fzx(z1,z2):logRzx={z1=x1z2=x2⊙exp(S(x1;θ))+T(x1;θ)i∑Si(x1;θ){x1=z1x2=(z2−T(x1;θ))⊙exp(−S(z1;θ))−i∑Si(z1;θ)
由此可以得到 RealNVP Block
(y1,y2)=fxy(x1,x2)(z1,z2)=fyz(y1,y2)
KL 散度的推导
隐空间中的 KL 散度
KL 散度定义如下
KL(q∣∣p)=∫q(x)[logq(x)−logp(x)]dx=−Hq−∫q(x)logp(x)dx
其中 Hq 是分布 q 的熵。根据定义,若将真实的 Boltzmann 分布记为 μ,生成的分布记为 q,那么
KL(μZ∣∣qZ)=−HZ−∫μZ(z)logqZ(z;θ)dz=−HZ−∫μZ(z)[logμX(Fzx(z;θ))+logRzx(z;θ)]dz=−HZ+logZX+Ez∼μZ(z)[u(Fzx(z;θ))−logRzx(z;θ)]
其中 ZX 满足
μX(x)=Zx−1e−βU(x)
由于在训练过程中 HZ 和 ZX 不随 θ 变化,可以将 KL 部分的损失函数写作
JKL=Ez∼μZ(z)[u(Fzx(z;θ))−logRzx(z;θ)]
若同时在多个温度下训练,那么
JKLT1,…,TK=k=1∑KEz∼μZk(z)[uk(Fzx(z;θ))−logRzx(z;θ)]
构象空间中的 KL 散度
类似的可以推导构象空间中的 KL 散度。
KLθ[μX∥qX]=HX−∫μX(x)logqX(x;θ)dx=HX−∫μX(x)[logμZ(Fxz(x;θ))+logRxz(z;θ)]dx.=HX+logZZ+Ex∼μ(x)[σ21∥Fxz(x;θ)∥2−logRxz(x;θ)]
其中 ZZ 满足
μZk(z)=ZZ−1exp(−2σk2∥z∥2)
由于从 μX 中进行采样是不现实的,因此这个散度项很难直接求算。但对于基于例子的训练来说,可以从给定的初始分布 ρ(x) 开始训练,此时
JML=−Ex∼ρ(x)[logqX(x;θ)]=Ex∼ρ(x)[σ21∥Fxz(x;θ)∥2−logRxz(x;θ)]
KL 散度与自由能
HX 可以改写如下
HX=−∫xqX(x)logqX(x)dx=−∫zqX(Fzx(z))log(qX(Fzx(z))Rzx(z))dz=−∫zμZ(z)logqX(Fzx(z))dz=−∫zμZ(z)log(μZ(z)Rzx(z)−1)dz=HZ+Ez∼μZ(z)[logRzx(z)]
代入 JKL 的表达式即有
JKL=U−HX+HZ
此外,可以证明
KLθ[μZ∣∣qZ]=−HZ+logZX+Ez∼μZ(z)[u(Fzx(z;θ))−logRzx(z;θ)]=−HX+logZX+Ez∼μZ(z)[u(Fzx(z;θ))]=−HZ+logZX+Ex∼μX(x;θ)[u(x)]=KLθ[qX∣∣μX]

